Get cases data
We use covid19bharat.org to get a tally of daily confirmed cases and then summarize it to monthly level.
indian_state_cases <- GetIndiaConfirmedCasesMonthlyLong()
india_cases <- indian_state_cases %>%
filter(State == "India") %>%
filter(value > 1)
head(india_cases)
#> MonthYear State value type
#> 1 Mar 2020 India 1635 Confirmed
#> 2 Apr 2020 India 33232 Confirmed
#> 3 May 2020 India 155781 Confirmed
#> 4 Jun 2020 India 395044 Confirmed
#> 5 Jul 2020 India 1111273 Confirmed
#> 6 Aug 2020 India 1990350 Confirmed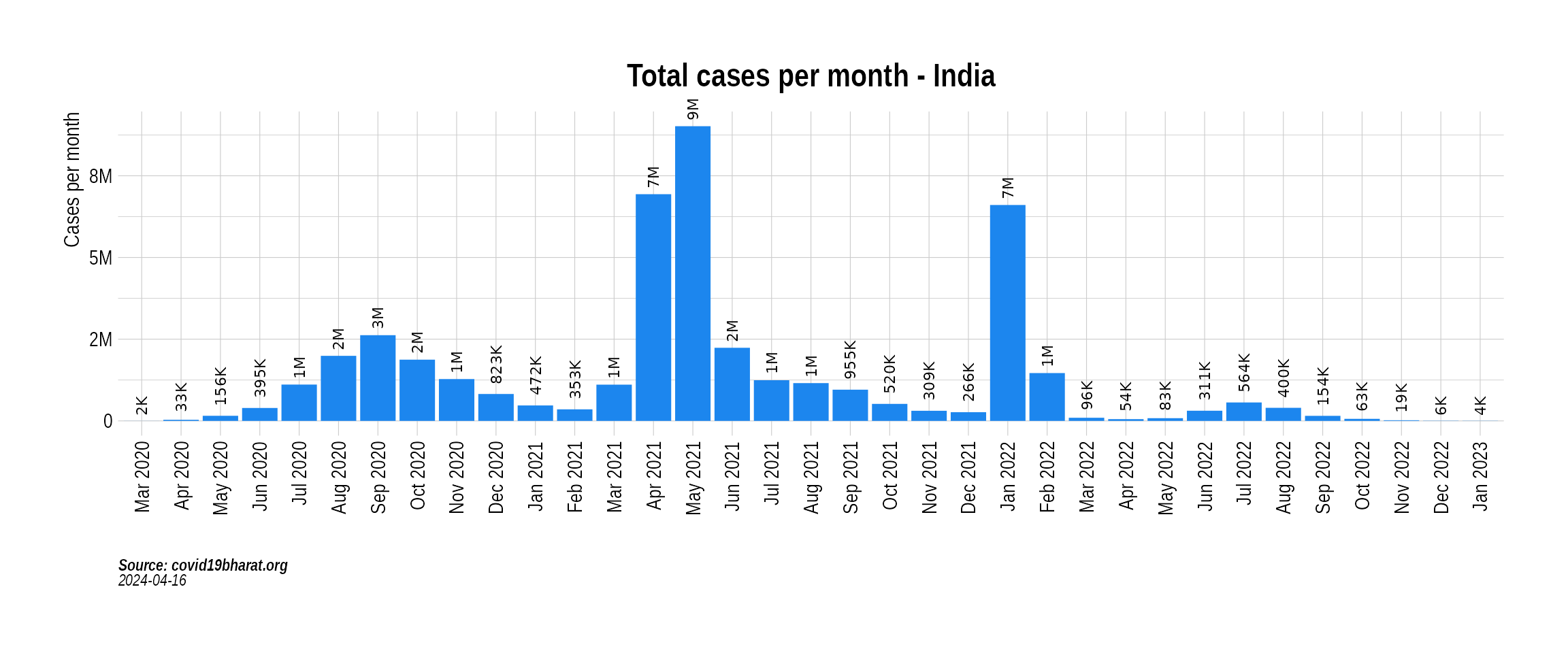
Read variant data from GISAID
We utilize GISAID data to look at prevalence of variants. To access this data, GISAID requires registration.
current_date <- "2024_04_11"
fpath.tar <- paste0("~/data/epicov/metadata_tsv_", current_date, ".tar.xz")
fpath.qs <- paste0("~/data/epicov/metadata_tsv_", current_date, ".qs")
if (file.exists(fpath.qs)) {
gisaid_metadata <- qs::qread(file = fpath.qs)
} else {
gisaid_metadata <- ReadGISAIDMetada(path = fpath.tar)
qs::qsave(gisaid_metadata, fpath.qs)
}Plot total sequenced cases
We can look at the absolute number of cases that have been sequenced from a country by filtering out information from the metadata made available by GISAID (which includes all countries). Here, we visualize the total sequenced cases coming from India:
gisaid_india <- FilterGISAIDIndia(gisaid_metadata_all = gisaid_metadata)
country_seq_stats <- TotalSequencesPerMonthCountrywise(gisaid_india, rename_country_as_state = TRUE)
p2 <- BarPlot(country_seq_stats, ylabel = "Sequenced per month", color = "slateblue1", label_si = TRUE, title = "Total sequences deposited to GISAID from India", caption = "**Source: gisaid.org **<br>")
p2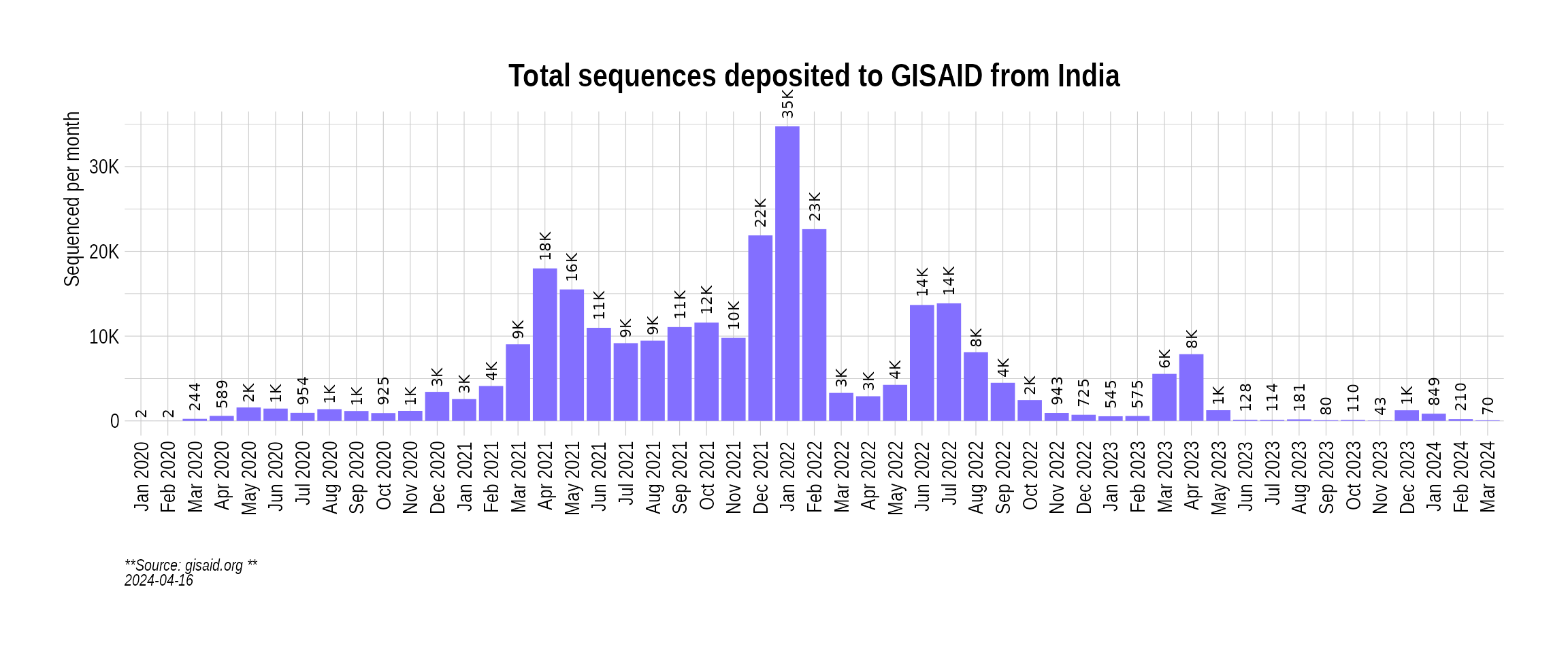
Overall, how much has India sequenced over months?
While the absolute numbers are informative, a more useful metric is the proportion of cases (cases sequenced over total cases) that are getting sequenced. Here we look at the proportion of cases that have been sequenced in India over the course of the pandemic:
# india_cases_long <- GetIndiaConfirmedCasesMonthlyLong() %>% filter(State == "India")
GetIndiaCases <- function() {
data <- read.csv("https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/cases_deaths/new_cases.csv")
confirmed <- data %>% select(date, India)
colnames(confirmed)[2] <- c("cases")
confirmed$MonthYear <- GetMonthYear(confirmed$date)
confirmed_subset_weekwise <- confirmed %>%
group_by(MonthYear) %>%
summarise(value = sum(cases, na.rm = T)) %>%
arrange(MonthYear)
}
india_cases_long <- GetIndiaCases()
india_cases_long$State <- "India"
india_cases_long$type <- "Confirmed"
india_sequencing_proportion <- CombineSequencedCases(
cases_sequenced = country_seq_stats,
confirmed_long = india_cases_long
)
p3 <- BarPlot(india_sequencing_proportion, yaxis = "percent_sequenced_collected", ylabel = "% deposited to GISAID", color = "yellowgreen", title = "Proportion of cases deposited to GISAID from India", caption = "**Source: gisaid.org and ourworldindata.org/coronavirus**<br>")
p3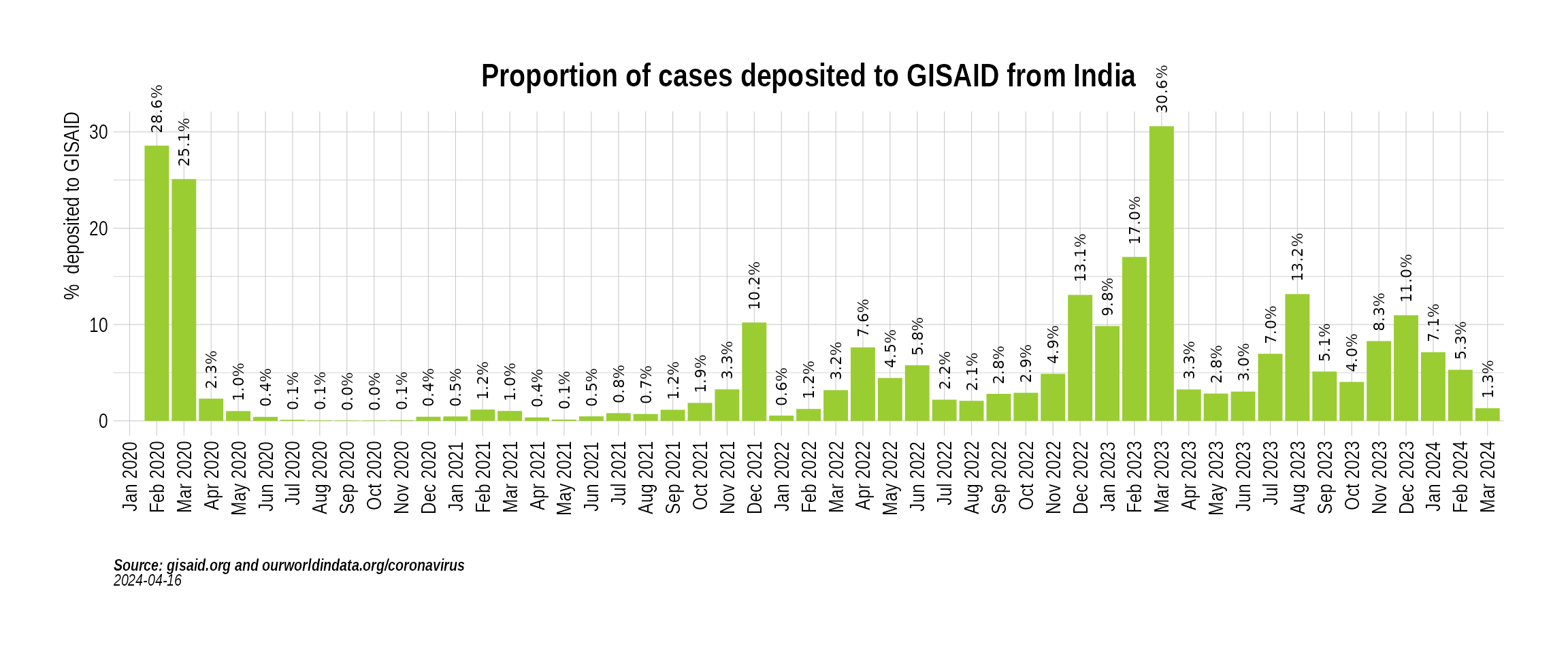
Plot proportion of cases that been deposited from each state
We can further break down the proportion of sequenced cases at the state level:
state_seq_stats <- TotalSequencesPerMonthStatewise(gisaid_india, drop_country = TRUE)
seq_stats <- rbind(country_seq_stats, state_seq_stats)
state_cases_long <- GetIndiaConfirmedCasesMonthlyLong()
india_sequencing_proportion <- CombineSequencedCases(
cases_sequenced = seq_stats,
confirmed_long = state_cases_long,
month.min = "Jan 2022",
month.max = "Feb 2023",
max.percent = 5
)
india_sequencing_proportion$State <- factor(
x = india_sequencing_proportion$State,
levels = as.character(GetIndianStates())
)
p4 <- PlotSequencedPropHeatmap(india_sequencing_proportion)
# p4Plot Prevalence
Finally, we look at the prevalence of variants and variants of concern (VOCs):
india_month_counts <- SummarizeVariantsMonthwise(gisaid_india)
india_month_counts$State <- "India"
india_month_prevalence <- CountsToPrevalence(india_month_counts)
vocs <- GetVOCs()
custom_voc_mapping <- list(
`JN.1` = "JN.1",
`JN.1.*` = "JN.1",
`HV.1` = "HV.1",
`HV.1.*` = "HV.1",
`B.1` = "B.1",
`B.1.1.306` = "B.1",
`B.1.1.306.*` = "B.1",
`B.1.1.326` = "B.1",
`B.1.36.29` = "B.1",
`B.1.560` = "B.1",
`B.1.1` = "B.1",
`B.1.210` = "B.1",
`B.1.36.8` = "B.1",
`B.1.36` = "B.1",
`B.1.36.*` = "B.1"
)
india_month_prevalence <- CollapseLineageToVOCs(
variant_df = india_month_prevalence,
vocs = vocs,
custom_voc_mapping = custom_voc_mapping, summarize = FALSE
)
p5 <- StackedBarPlotPrevalence(india_month_prevalence)
p5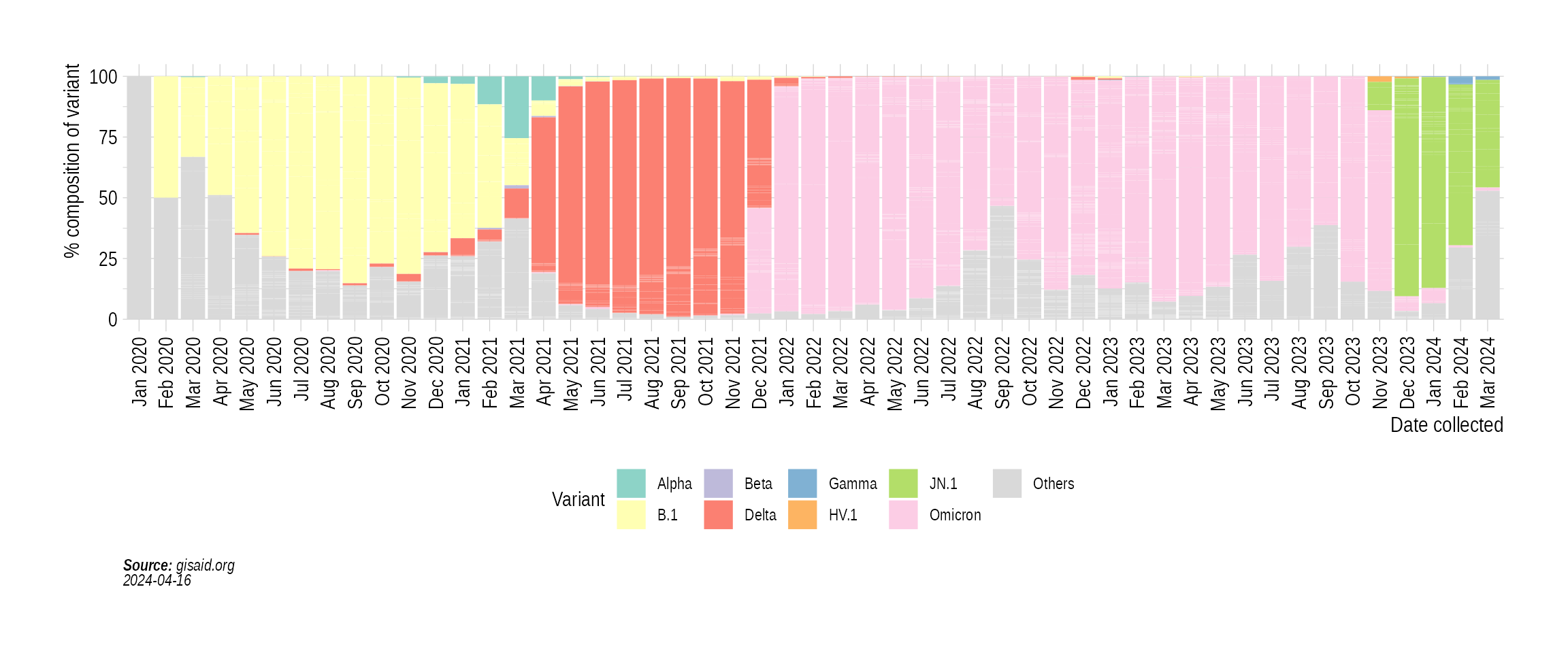
For an animated version of the prevalence plot, check out VariantAnimation.